Types of caching and its strategies in backend
December 30, 2023
This blogpost is for my future self who will want to quickly brush up on caching in case he forgets about it. Just like I still refer to my redis persistence post often times.
Alright let’s start.
That picture you download from right clicking on it? or that series you binge-watched from netflix? or the simple act of you coming online and googling something? All these things(and much more) are served by caches around the world and the one most near you.
To be quiet honest, caching is a very wide term which encompasses a lot of different types, each of which serves the same purpose(delivering the content faster) but are used at different stages of your internet journey.
Credit: https://aws.amazon.com/caching
All the stages represented in the above picture use caches. I won’t be explaining each of them except Server(Application) side caching.
What is caching?
Caching is a technique that stores data temporarily in a cache. The purpose of caching is to improve the performance of an application by reducing the time it takes to retrieve data.
Different Types of Caching Strategies in backend
You will see a lot more caching strategies out there in the world and below as well.
How you choose the most suitable caching strategy depends on your database’s read and write patterns.
Ask yourself how frequently is the data updated in this table? How frequently does my application read from DB right now? How fresh should your data be in the cache?
Answering the above questions can help you choose a caching strategy.
Cache Aside (Lazy Loading)
Cache Aside strategy is probably the most simplest of the strategy.
This is handled by the backend server. When it receives a request for some data, it checks the cache store and if the data is present(i.e. cache hit), it returns the data.
If the data is not present in the cache, then the server fetches the data from the on-disk DB and returns to the user.
It’s that simple 🤷
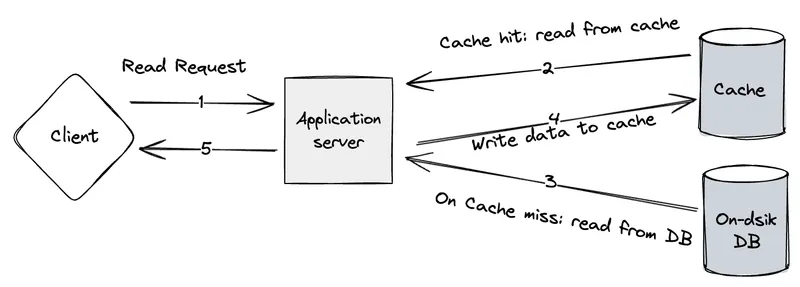
Read through caching
This is very similar to the Cache Aside strategy except the fetching and updation of the cache is handled by a separate library or a cache provider.
So if a server receives a read request, then it passes that request to a cache provider. The cache provider checks if the data is present in the cache. If it’s a cache miss, then it fetches the data from the on-disk DB.

Write through caching
This strategy is generally useful when the writes are less or the client is okay with mildly higher latencies but the read requests are high.
The higher latency is because when the server receives a request to insert data into DB, it also inserts the data into the cache store.
Keep in mind that if you have not implemented read-through caching with this, be sure to also update the cache when user sends a request to update the DB also.
Write behind or Write back caching
In write-behind caching, when data is written, it is first recorded in the cache and not immediately written to the primary storage or database.
The data in the cache is eventually written to the primary storage, but this happens after a delay. The delay can be based on time, certain triggers, or when the cache reaches a specific fill level.
There are certain advantages of these caching strategy:
- Performance Improvement: Since write operations are initially directed to the fast cache, this method can significantly improve the performance of write operations.
- Reduced Load on Primary Storage: By aggregating multiple write operations in the cache before they are written to the primary storage, it reduces the number of write operations.
- Batch Processing: It allows for batch processing of writes, which can be more efficient than individual writes, especially for systems where write operations are expensive!
The logic for deciding when to write back the data to the primary storage can be complex and needs to be carefully managed to ensure performance benefits without risking data integrity.
Helpful in scenarios where write performance is critical and there is tolerance for a slight delay in data persistence. Examples include high-transaction systems like stock trading platforms, or systems where write operations are significantly more resource-intensive than read operations.
Write around caching
In write-around caching, when data is written, it is written directly to the on-disk DB and not immediately placed in the cache.
The idea is to bypass the cache for write operations to prevent the cache from being filled with data that might not be read again soon, which is known as cache pollution.
Refresh Ahead
In refresh-ahead caching, the system anticipates future data requests based on previous access patterns or specific algorithms.
Before the data is actually requested by the client or application, the cache proactively updates or loads this anticipated data from the primary storage (like a database) into the cache.
So a usecase is when you are watching a movie on netflix, the server knows you will most likely keep watching so it loads up the next video segments proactively inside the cache to serve it faster. It reduces the load on the primary storage(video segments present on the disk)
If you would like to tell me more about this or have suggestions, feel free to DM me on twitter or email me at shivamsinghal5432 [at] gmail [dot] com!
# Bonus
I also tried to implement the read through and write through cache strategies in Go. It’s a very barebones web application without tests or data validation but that’s not related to caching so it’s okay!